音声認識の認識率とは?
音声認識の指標値について
音声認識はより広い意味を持ちますが、ここでは自然言語の音声のテキスト化(Speech to text)における認識率について説明します。
音声のテキスト化の評価を行う際、出力の正しさを何らかの形で数字にして評価する必要が生じます。
複数のシステムを比較する際や、音声認識システムに変更を加える前後で数値化して比較することが必要となってきます。
音声認識の認識率の指標値としては単語の誤り率 (WER: Word Error Rate) という値を使うことが出来ます。WERは音声認識システムの出力と正解文を比較することで得られる指標値です。
WERは以下の数式で表されていますが、認識誤りの総和を単語数で割ったものとなります。
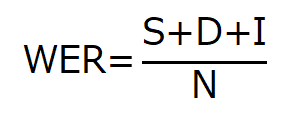
この数式中の変数 S, D, I, N は以下のようになっています。
| 変数 | 説明 |
|---|---|
| S (Substitution) | 差分(認識違い)、違う単語として認識されている |
| D (Deletion) | 削除(認識もれ)、存在するはずの単語を認識していない |
| I (Insertion) | 挿入、存在しないはずの単語が出力されている |
| N (Number of words) | 正解の単語数 |

日本語における単語について
音声認識が認識対象とする言語の中で意味を持った単位が「単語」となりますが、
英語のような単語が明確に分かれている言語と異なり、日本語の文章では単語は句読点以外は連結されているのが普通なので、単語の分割は自明ではありません。
機械的に日本語を単語単位に分解する方法として形態素解析という方法があります。形態素は言語学的な意味を持つ最小単位です。
たとえば「今日はいい天気です」というフレーズを形態素解析で分解すると、以下のように分解されます。
| 単語 | 品詞 |
|---|---|
| 今日 | 普通名詞 |
| は | 係助詞 |
| いい | 形容詞-連体形 |
| 天気 | 普通名詞 |
| です | 助動詞-終止形 |
文字単位の誤り率
単語の誤り率を求める代わりに、文字の誤り率 (CER: Character Error Rate) を用いる場合もあります。文字単位であればどうやって単語に分割するか悩まずに済みますが、意味が正しいかどうかという観点では文字が1つ違えばその前後の文字も含めておかしくなることが多いので、文字単位で比較することには疑問があります。
また、日本語の場合は文字単位での評価が楽でも、他の言語における認識率と比較することが出来なくなります。

認識率の注意事項
音声のテキスト化における認識率という数字は比較するには便利に見えますが、一方で注意すべき点もあります。
認識率は全ての単語を等じように評価しますが、発話の中には重要な単語とそうでない単語があります。
代表例はフィラーと呼ばれる、「えー」とか「あー」のように単語間に挿入される意味のない単語で、
これを正しく認識することは音声認識のプロセスとしては必要かもしれませんが、言語としては無価値です。
使われ方によっては認識すべきキーワードを正確に認識することの方が価値があります。
評価時は認識率という一つの数字だけではなく、目的にそった総合的な判断をするべきでしょう。
音声認識システムの出力形式
音声認識システムによって出力される単語は変わってきますので、正解文と比較する際に形式はそろえる必要があります。
例えば、人名の出力は「佐藤」と漢字で出力される場合も、「さとう」「サトウ」のように平仮名や片仮名で出力される場合もあります。
また、数字は「百万」「100万」「1000000」「1,000,000」のように出力方法はいろいろあります。
フィラーのような意味の無い単語は出力を行わないシステムもあります。

日本語の漢字かな混じり文では漢字に送り仮名がついているケースがありますが、送り仮名のつけ方には表記ゆれが存在します。 一般的には内閣告示の基準が広く使われているので、それを用いるのがよいと考えられます。
カタカナ語についても表記ゆれが存在し、音声認識システム内の辞書により出力が変わってきます。
「コンピュータ」と「コンピューター」のように、どちらが発声されていたのか?とは別にどちらが出力されるか?という問題が生じます。カタカナの表記についてはガイドラインが存在するので、それに従うのがひとまず妥当だと思われます。
固有名詞の中には「グーグル」と「Google」のようにどちらで出力されるべきか?悩ましいケースがあります。
出力形式の差分まで考慮して機械的に認識率を求めるのは難しいため、正解文を作成する際に形式を揃えておく必要があります。
正解文の作成
あらかじめテキストを用意して、それを読み上げることで音声データを作成した、読み上げデータを音声認識の対象とする場合は正解文が存在しますが、録音で自然な音声を収集して音声認識にかける場合、実際に人が録音を聞いて人手で書き起こし作業を行う必要があります。
統計処理
音声認識は各種条件により変化するため、単一の評価サンプルではなく、複数の評価サンプルについて試験を行い、その平均値、中央値、標準偏差、最良値、最悪値等で結果の分布を確認する必要があります。
統計的に正確な結果を求めたい場合は十分な量の評価サンプルを用意する必要があります。
評価サンプルの録音時間に差異がある場合、評価サンプル毎のWERの平均だと、不均衡が生じる恐れがあります。
録音の長さの影響を排除する方法として、評価ファイル全ての単語について、WERを一括で求める方法があります。